



Veri Bilimine Adım Adım Yol Haritası: Sıfırdan Veri Bilimci Olmak
- emrerdin0
- 1 Ağu 2025
- 13 dakikada okunur

Veri bilimi, günümüzün en hızlı büyüyen ve en heyecan verici alanlarından biridir. Büyük veri setlerinden anlamlı içgörüler elde etme, geleceği tahmin etme ve karmaşık problemleri çözme yeteneği, veri bilimcileri birçok sektörde vazgeçilmez kılmaktadır. Eğer programlama bilginiz olmasa bile, bu alana sıfırdan başlamak ve başarılı bir veri bilimci olmak kesinlikle mümkündür. Bu kapsamlı yol haritası, sizi veri biliminin temel taşlarından başlayarak gerçek dünya projeleri geliştirmeye ve kendinizi profesyonel olarak tanıtmaya kadar adım adım yönlendirecektir.
Bu blog yazısı, veri bilimi yolculuğunuzda size rehberlik edecek, her aşamada hangi konulara odaklanmanız gerektiğini, dikkat etmeniz gereken temel noktaları ve ücretsiz, kaliteli kaynak önerilerini sunacaktır. Ayrıca, her bölüm için pratik proje fikirleri ve uygulama önerileriyle öğrendiklerinizi pekiştirmenize yardımcı olacağız. Hazırsanız, veri bilimi dünyasına doğru bu heyecan verici yolculuğa başlayalım!
Aşama 1: Python Temelleri ve Veri Bilimi Kütüphaneleri
Veri bilimi yolculuğunuzun ilk ve en kritik adımı, Python programlama dilini öğrenmektir. Python, basit sözdizimi, geniş kütüphane desteği ve büyük bir topluluğa sahip olması nedeniyle veri bilimi alanında de facto standart haline gelmiştir. Programlama geçmişiniz olmasa bile, Python'ın öğrenme eğrisi oldukça düşüktür ve temel kavramları hızla kavrayabilirsiniz.
Alt Konular:
Python Programlama Temelleri: Değişkenler, veri tipleri (sayılar, dizeler, listeler, demetler, sözlükler), operatörler, koşullu ifadeler (if-elif-else), döngüler (for, while), fonksiyonlar, modüller ve paketler. Bu temel yapı taşları, daha karmaşık veri manipülasyonları ve analizleri için sağlam bir zemin oluşturacaktır.
NumPy (Numerical Python): Bilimsel hesaplamalar için temel bir kütüphanedir. Özellikle çok boyutlu diziler (ndarray) ve matris işlemleri için optimize edilmiştir. Büyük veri setleriyle hızlı ve verimli çalışmak için vazgeçilmezdir. NumPy ile vektör ve matris operasyonlarını öğrenmek, makine öğrenmesi algoritmalarının arkasındaki matematiksel işlemleri anlamanıza yardımcı olacaktır.
Pandas (Python Data Analysis Library): Veri manipülasyonu ve analizi için en güçlü kütüphanelerden biridir. DataFrame adı verilen tablo benzeri veri yapıları sunar. Veri okuma (CSV, Excel, SQL), temizleme, dönüştürme, birleştirme ve özetleme gibi görevleri kolayca yapmanızı sağlar. Gerçek dünya veri setleriyle çalışırken zamanınızın büyük bir kısmını Pandas ile geçirmelisiniz.
Dikkat Edilmesi Gereken Temel Noktalar:
Temiz ve Okunabilir Kod Yazma: Sadece çalışan değil, aynı zamanda başkaları tarafından kolayca anlaşılabilecek ve sürdürülebilecek kod yazmaya özen gösterin. Yorumlar, anlamlı değişken adları ve fonksiyon kullanımı bu konuda size yardımcı olacaktır.
Hata Ayıklama (Debugging): Kodunuzda oluşan hataları (bug) bulma ve düzeltme becerisi, programlama sürecinin ayrılmaz bir parçasıdır. Hata mesajlarını okumayı, print() fonksiyonunu kullanarak değişken değerlerini kontrol etmeyi ve bir hata ayıklayıcı (debugger) kullanmayı öğrenin.
Pratik Yapmak: Öğrendiğiniz her konuyu küçük kod parçacıkları yazarak pekiştirin. Sadece okumak veya video izlemek yeterli değildir; aktif olarak kod yazmak, kas hafızası oluşturmanızı ve problem çözme becerilerinizi geliştirmenizi sağlar.
Ücretsiz ve Kaliteli Kaynak Önerileri:
Python Resmi Dokümantasyonu: Python'ın en güncel ve kapsamlı kaynağıdır. Başlangıç seviyesi için biraz yoğun olabilir, ancak bir referans kaynağı olarak her zaman elinizin altında bulunmalıdır [1].
Codecademy: İnteraktif derslerle Python temellerini öğrenmek için harika bir platformdur. Kod yazma alıştırmalarıyla pratik yapma imkanı sunar.
Coursera / edX: Birçok üniversitenin ve kurumun ücretsiz veya deneme sürümü sunan Python ve veri bilimi kursları bulunmaktadır. Örneğin, Michigan Üniversitesi'nin
"Python for Everybody Specialization" veya IBM'in "Python for Data Science and AI" kursları başlangıç için idealdir.
W3Schools Python Tutorial: Basit ve anlaşılır bir dille Python temellerini öğrenmek için iyi bir kaynaktır.
Proje Fikirleri ve Pratik Öneriler:
Basit Veri Manipülasyonu: Kendi küçük veri setlerinizi (örneğin, favori filmlerinizin listesi, arkadaşlarınızın doğum günleri) oluşturun ve Python listeleri, sözlükleri kullanarak bu verileri sıralama, filtreleme, ekleme gibi temel manipülasyonlar yapın.
CSV Dosyası Okuma/Yazma: Pandas kütüphanesini kullanarak basit bir CSV dosyasını okuyun, içeriğini görüntüleyin, bazı sütunları seçin ve yeni bir CSV dosyasına yazın. Örneğin, bir ülkenin nüfus verilerini içeren bir CSV dosyasını okuyup, belirli bir yıl aralığındaki nüfus artışını hesaplayabilirsiniz.
Temel NumPy Operasyonları: Küçük NumPy dizileri oluşturun, bu diziler üzerinde toplama, çıkarma, çarpma gibi temel matematiksel işlemleri uygulayın. İki matrisi çarpın veya bir matrisin transpozunu alın.
Kaggle Notebooks İncelemesi: Kaggle platformunda (veri bilimcilerin projelerini paylaştığı bir topluluk) yeni başlayanlar için yazılmış Python ve Pandas ağırlıklı notebook'ları inceleyin. Başkalarının kodlarını okumak ve anlamak, kendi kodlama becerilerinizi geliştirmenin harika bir yoludur.
[1] Python Resmi Dokümantasyonu: https://docs.python.org/3/
Aşama 2: Veri Analizi ve Veri Görselleştirme
Python temellerini ve Pandas ile NumPy kütüphanelerini öğrendikten sonra, veri biliminin kalbine, yani veri analizi ve görselleştirmeye geçebilirsiniz. Bu aşama, ham veriden anlamlı içgörüler çıkarmak ve bu içgörüleri etkili bir şekilde sunmak için kritik öneme sahiptir.
Alt Konular:
Veri Temizleme ve Ön İşleme: Gerçek dünya verileri genellikle eksik, hatalı veya tutarsızdır. Bu alt başlık altında, eksik değerleri doldurma veya silme, aykırı değerleri (outliers) tespit etme ve düzeltme, veri tiplerini dönüştürme, metin verilerini işleme (tokenization, stemming, lemmatization) gibi teknikleri öğrenmelisiniz. Temiz veri, doğru analizlerin temelidir.
Keşifçi Veri Analizi (EDA - Exploratory Data Analysis): EDA, bir veri setini anlamak, ana özelliklerini özetlemek ve potansiyel kalıpları, anormallikleri veya ilişkileri ortaya çıkarmak için yapılan ilk analiz sürecidir. İstatistiksel özetler (ortalama, medyan, standart sapma), frekans dağılımları ve korelasyon analizleri gibi yöntemler kullanılır. EDA, hipotezler oluşturmanıza ve sonraki analiz adımlarını planlamanıza yardımcı olur.
Matplotlib: Python'da statik, etkileşimli ve animasyonlu görselleştirmeler oluşturmak için kullanılan temel bir çizim kütüphanesidir. Çizgi grafikleri, dağılım grafikleri (scatter plots), çubuk grafikleri (bar charts), histogramlar ve kutu grafikleri (box plots) gibi temel grafik türlerini oluşturmayı öğrenmelisiniz. Matplotlib, görselleştirmeler üzerinde yüksek düzeyde kontrol sağlar.
Seaborn: Matplotlib üzerine inşa edilmiş, daha estetik ve istatistiksel grafikler oluşturmayı kolaylaştıran bir kütüphanedir. Karmaşık görselleştirmeleri daha az kodla yapmanızı sağlar ve istatistiksel ilişkileri keşfetmek için özel grafik türleri sunar (örneğin, ısı haritaları, çift grafikleri). Seaborn, özellikle EDA sırasında hızlı ve bilgilendirici görselleştirmeler için idealdir.
Plotly (İsteğe Bağlı): Etkileşimli ve web tabanlı görselleştirmeler oluşturmak için güçlü bir kütüphanedir. Grafikleri yakınlaştırma, kaydırma ve veri noktaları üzerinde gezinme gibi özellikler sunar. Özellikle web uygulamalarında veya interaktif raporlarda veri sunumu için kullanışlıdır.
Dikkat Edilmesi Gereken Temel Noktalar:
Veri Kalitesi ve Güvenilirliği: Analize başlamadan önce verinin kalitesini anlamak ve olası sorunları gidermek çok önemlidir.
Veri setinin nasıl toplandığını, hangi varsayımların yapıldığını ve olası önyargıları (bias) sorgulayın.
Doğru Görselleştirme Türünü Seçme: Her görselleştirme türü farklı bir amaca hizmet eder. Veri setinizdeki ilişkiyi, dağılımı, kompozisyonu veya karşılaştırmayı en iyi şekilde anlatacak grafik türünü seçmek, mesajınızı etkili bir şekilde iletmek için kritiktir.
Hikaye Anlatımı: Veri görselleştirme sadece grafik çizmek değildir; verilerle bir hikaye anlatmaktır. Görselleştirmelerinizin başlıkları, etiketleri ve renkleri anlaşılır olmalı ve izleyiciyi belirli bir sonuca yönlendirmelidir.
Ücretsiz ve Kaliteli Kaynak Önerileri:
Kaggle: Gerçek dünya veri setleri bulmak, başkalarının analizlerini (notebook'larını) incelemek ve kendi analizlerinizi yapmak için en iyi platformlardan biridir. Özellikle "Titanic: Machine Learning from Disaster" gibi başlangıç seviyesi yarışmaları, veri temizleme ve EDA becerilerinizi geliştirmek için harikadır.
DataCamp / Datacamp: Veri analizi ve görselleştirme üzerine interaktif kurslar sunar. Ücretsiz modülleri ile temel kavramları öğrenebilirsiniz.
YouTube Kanalları: Corey Schafer, Sentdex, Krish Naik gibi kanallar, Python, Pandas, Matplotlib ve Seaborn üzerine detaylı ve uygulamalı eğitim videoları sunmaktadır.
Seaborn ve Matplotlib Resmi Galerileri: Bu kütüphanelerin resmi web sitelerindeki galeriler, farklı grafik türlerini ve kod örneklerini görmek için harika birer kaynaktır.
Proje Fikirleri ve Pratik Öneriler:
Bir Veri Setini Temizleme ve EDA Yapma: Kaggle'dan ilgi alanınıza uygun bir veri seti (örneğin, film verileri, spor istatistikleri, hava durumu verileri) indirin. Bu veri setindeki eksik değerleri doldurun, hatalı verileri düzeltin ve temel istatistiksel özetlerini çıkarın. Veri setindeki değişkenler arasındaki ilişkileri keşfetmek için korelasyon matrisleri ve dağılım grafikleri kullanın.
Farklı Grafik Türleri ile Görselleştirme: Aynı veri setini kullanarak Matplotlib ve Seaborn ile farklı grafik türleri oluşturun. Örneğin, zaman içindeki bir değişimi göstermek için çizgi grafiği, kategorik verileri karşılaştırmak için çubuk grafiği, iki sayısal değişken arasındaki ilişkiyi göstermek için dağılım grafiği kullanın.
İnteraktif Bir Gösterge Paneli (Dashboard) Oluşturma (İleri Seviye): Plotly veya diğer kütüphaneler (örneğin, Dash, Streamlit) kullanarak, kullanıcıların verileri filtreleyebileceği ve farklı görselleştirmeleri interaktif olarak keşfedebileceği basit bir web tabanlı gösterge paneli oluşturun.
Aşama 3: Temel İstatistik ve Olasılık Bilgisi
Veri bilimi, sadece kod yazmak ve görselleştirmeler oluşturmaktan ibaret değildir. Verilerin arkasındaki anlamı kavramak, hipotezleri test etmek ve sonuçları güvenilir bir şekilde yorumlamak için sağlam bir istatistik ve olasılık temeline sahip olmak zorunludur. Bu aşama, veri bilimci olarak aldığınız kararların bilimsel dayanağını oluşturacaktır.
Alt Konular:
Tanımlayıcı İstatistikler (Descriptive Statistics): Veri setlerinin ana özelliklerini özetlemek ve tanımlamak için kullanılan yöntemlerdir. Merkezi eğilim ölçüleri (ortalama, medyan, mod), yayılım ölçüleri (varyans, standart sapma, çeyreklikler, ranj) ve şekil ölçüleri (çarpıklık, basıklık) gibi kavramları öğrenmelisiniz. Bu istatistikler, veri setinizi tek sayılarla veya grafiklerle anlamanıza yardımcı olur.
Olasılık Teorisi (Probability Theory): Belirsizlik altındaki olayların matematiksel olarak modellenmesidir. Temel olasılık kavramları (olay, örneklem uzayı, koşullu olasılık, bağımsızlık), olasılık dağılımları (Bernoulli, Binom, Poisson, Normal dağılım) ve Bayes Teoremi gibi konuları kapsar. Makine öğrenmesi algoritmalarının çoğu olasılık teorisine dayanır.
Çıkarımsal İstatistikler (Inferential Statistics): Bir örneklemden elde edilen verileri kullanarak daha büyük bir popülasyon hakkında çıkarımlar yapma yöntemleridir. Güven aralıkları (confidence intervals) ve hipotez testleri (t-testi, ANOVA, ki-kare testi) bu bölümün ana konularıdır. Bu sayede, verilerinizden elde ettiğiniz sonuçların genellenebilirliğini değerlendirebilirsiniz.
Korelasyon ve Regresyon: Değişkenler arasındaki ilişkileri ölçmek için kullanılan istatistiksel yöntemlerdir. Korelasyon, iki değişken arasındaki ilişkinin yönünü ve gücünü gösterirken, regresyon (basit doğrusal regresyon, çoklu doğrusal regresyon) bir veya daha fazla bağımsız değişken kullanarak bağımlı bir değişkeni tahmin etmeyi amaçlar.
Dikkat Edilmesi Gereken Temel Noktalar:
İstatistiksel Düşünme: Sadece formülleri ezberlemek yerine, her istatistiksel kavramın arkasındaki mantığı ve ne anlama geldiğini anlamaya çalışın. Neden belirli bir istatistiksel yöntemi kullandığınızı ve sonuçlarının ne gibi çıkarımlara yol açtığını sorgulayın.
Sonuçları Yorumlama: İstatistiksel analizlerden elde ettiğiniz p-değerleri, güven aralıkları veya regresyon katsayıları gibi sonuçları doğru bir şekilde yorumlamak, veri bilimci olarak en önemli becerilerinizden biridir. Teknik terimleri basit bir dille açıklayabilme yeteneği, bulgularınızı paydaşlara aktarırken çok değerlidir.
Varsayımları Anlama: Birçok istatistiksel test ve model, belirli varsayımlara dayanır (örneğin, verilerin normal dağılması). Bu varsayımların ihlal edilmesi, sonuçlarınızın geçersiz olmasına neden olabilir. Her yöntemin varsayımlarını öğrenin ve verilerinizin bu varsayımları karşılayıp karşılamadığını kontrol edin.
Ücretsiz ve Kaliteli Kaynak Önerileri:
Khan Academy - İstatistik ve Olasılık: Temel istatistik ve olasılık kavramlarını adım adım, anlaşılır örneklerle anlatan harika bir kaynaktır. İnteraktif alıştırmalarla pekiştirme imkanı sunar [2].
Coursera / edX: Duke Üniversitesi'nin "Introduction to Statistics" veya Stanford Üniversitesi'nin "Probability and Statistics for Data Science" gibi kursları, bu konularda derinlemesine bilgi edinmek için idealdir.
YouTube Kanalları: StatQuest with Josh Starmer, 365 Data Science gibi kanallar, istatistik ve olasılık kavramlarını görsel ve sezgisel bir şekilde açıklamaktadır.
NYU - Probability and Statistics for Data Science (PDF): Kapsamlı ders notları içeren ücretsiz bir PDF kaynağıdır. Matematiksel temelleri daha derinlemesine anlamak isteyenler için faydalıdır [3].
Proje Fikirleri ve Pratik Öneriler:
Basit Bir Veri Setinde Hipotez Testi Uygulama: İki farklı grubun (örneğin, yeni bir ilacı alanlar ve almayanlar) ortalamaları arasında anlamlı bir fark olup olmadığını test etmek için bir t-testi uygulayın. Sonuçları yorumlayın ve hipotezinizi kabul edip etmediğinizi açıklayın.
Dağılım Analizi Yapma: Bir veri setindeki sayısal bir değişkenin (örneğin, öğrenci notları, ev fiyatları) dağılımını inceleyin. Histogramlar ve kutu grafikleri kullanarak dağılımın şeklini, merkezi eğilimini ve yayılımını görselleştirin. Normal dağılıma uygun olup olmadığını test edin.
Korelasyon ve Regresyon Analizi: İki sayısal değişken arasındaki ilişkiyi (örneğin, çalışma saatleri ile sınav notları) inceleyin. Korelasyon katsayısını hesaplayın ve bir dağılım grafiği çizin. Basit doğrusal regresyon modeli oluşturarak bir değişkeni diğerine göre tahmin etmeye çalışın ve modelin performansını değerlendirin.
Gerçek Dünya Verileriyle Olasılık Hesapları: Hava durumu tahminleri, spor müsabakaları sonuçları veya borsa hareketleri gibi gerçek dünya verileri üzerinde basit olasılık hesapları yapın. Örneğin, belirli bir hisse senedinin yarın yükselme olasılığını geçmiş verilere dayanarak tahmin edin.
[2] Khan Academy - İstatistik ve Olasılık: https://www.khanacademy.org/math/statistics-probability
[3] NYU - Probability and Statistics for Data Science (PDF): https://cims.nyu.edu/~cfgranda/pages/stuff/probability_stats_for_DS.pdf
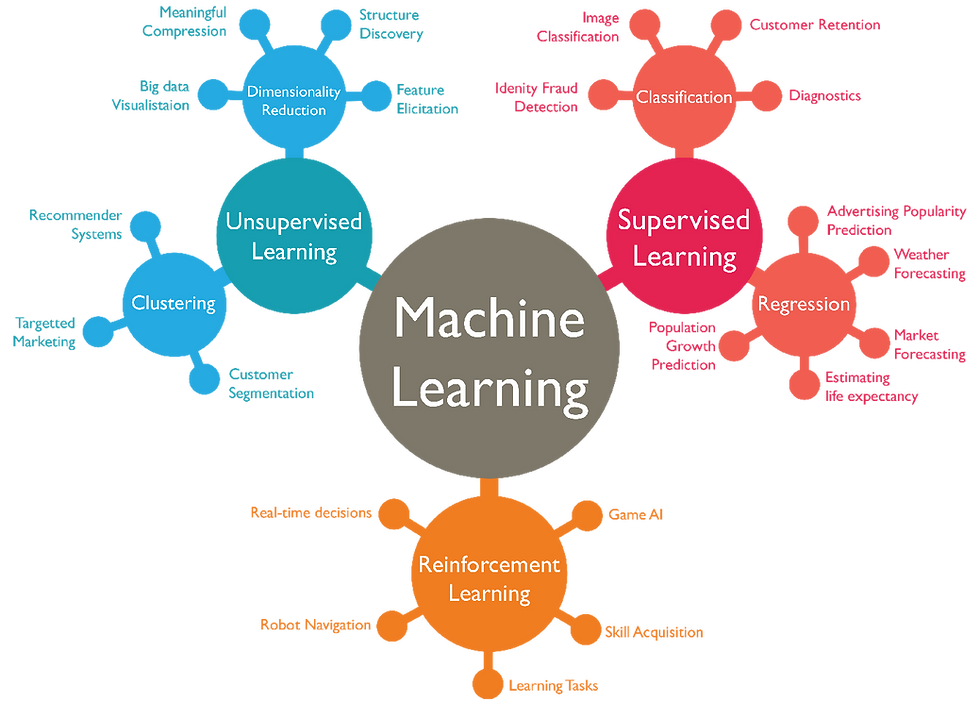
Aşama 4: Makine Öğrenmesi ve Modeller
Veri bilimi yolculuğunuzun en heyecan verici ve talep gören aşamalarından biri makine öğrenmesidir. Makine öğrenmesi, bilgisayarların açıkça programlanmadan verilerden öğrenmesini ve bu öğrenilen bilgiyi kullanarak tahminler yapmasını veya kararlar almasını sağlayan yapay zekanın bir alt dalıdır. Bu aşamada, farklı makine öğrenmesi algoritmalarını, nasıl çalıştıklarını ve gerçek dünya problemlerini çözmek için nasıl uygulanacaklarını öğrenmelisiniz.
Alt Konular:
Makine Öğrenmesine Giriş: Makine öğrenmesinin ne olduğu, neden önemli olduğu, denetimli öğrenme (supervised learning), denetimsiz öğrenme (unsupervised learning) ve pekiştirmeli öğrenme (reinforcement learning) gibi temel paradigmalar. Ayrıca, modelin eğitim, doğrulama ve test setlerine ayrılması gibi temel kavramlar.
Denetimli Öğrenme Algoritmaları:
Regresyon: Sürekli bir hedef değişkeni tahmin etmek için kullanılır (örneğin, ev fiyatı tahmini, hisse senedi fiyatı tahmini). Doğrusal Regresyon (Linear Regression), Polinom Regresyon (Polynomial Regression), Karar Ağaçları (Decision Trees), Destek Vektör Makineleri (Support Vector Machines - SVM) ve Rastgele Ormanlar (Random Forests) gibi algoritmaları öğrenmelisiniz.
Sınıflandırma: Kategorik bir hedef değişkeni tahmin etmek için kullanılır (örneğin, e-postanın spam olup olmadığı, müşterinin ürünü satın alıp almayacağı). Lojistik Regresyon (Logistic Regression), K-En Yakın Komşu (K-Nearest Neighbors - KNN), Karar Ağaçları, Destek Vektör Makineleri, Rastgele Ormanlar ve Naive Bayes gibi algoritmaları incelemelisiniz.
Denetimsiz Öğrenme Algoritmaları:
Kümeleme (Clustering): Veri noktalarını benzerliklerine göre gruplara ayırmak için kullanılır (örneğin, müşteri segmentasyonu, belge sınıflandırması). K-Means, Hiyerarşik Kümeleme (Hierarchical Clustering) ve DBSCAN gibi algoritmaları öğrenmelisiniz.
Boyut Azaltma (Dimensionality Reduction): Veri setindeki özellik sayısını azaltarak modelin karmaşıklığını düşürmek ve görselleştirmeyi kolaylaştırmak için kullanılır. Temel Bileşen Analizi (Principal Component Analysis - PCA) en yaygın kullanılan yöntemlerden biridir.
Model Değerlendirme ve Optimizasyon: Bir makine öğrenmesi modelinin ne kadar iyi performans gösterdiğini ölçmek için kullanılan metrikler ve teknikler. Regresyon için R-kare, Ortalama Mutlak Hata (MAE), Ortalama Kare Hata (MSE); sınıflandırma için Doğruluk (Accuracy), Hassasiyet (Precision), Duyarlılık (Recall), F1-Skor, ROC Eğrisi ve AUC gibi metrikler. Ayrıca, çapraz doğrulama (cross-validation), hiperparametre optimizasyonu (Grid Search, Random Search) ve aşırı öğrenme (overfitting) ile eksik öğrenme (underfitting) sorunlarını giderme teknikleri.
Scikit-learn: Python için en popüler ve kapsamlı makine öğrenmesi kütüphanesidir. Birçok makine öğrenmesi algoritmasını, veri ön işleme araçlarını ve model değerlendirme metriklerini içerir. Scikit-learn, hızlı prototipleme ve model geliştirme için vazgeçilmezdir.
Dikkat Edilmesi Gereken Temel Noktalar:
Model Seçimi: Her problem için tek bir en iyi model yoktur. Veri setinizin yapısına, problem türüne (regresyon, sınıflandırma vb.) ve performans gereksinimlerine göre doğru modeli seçmek önemlidir. Farklı modelleri deneyerek ve performanslarını karşılaştırarak en uygun olanı bulmaya çalışın.
Aşırı Öğrenme (Overfitting) ve Eksik Öğrenme (Underfitting): Bu iki kavram, makine öğrenmesinde sıkça karşılaşılan problemlerdir. Aşırı öğrenme, modelin eğitim verisine aşırı uyum sağlayıp yeni verilere genelleme yapamaması; eksik öğrenme ise modelin eğitim verisini bile yeterince öğrenememesidir. Bu durumları tespit etmeyi ve gidermeyi öğrenmek, başarılı modeller oluşturmanın anahtarıdır.
Doğruluk Metrikleri: Sadece modelin doğruluğuna (accuracy) odaklanmak yanıltıcı olabilir, özellikle dengesiz veri setlerinde. Problem türüne göre (örneğin, sınıflandırmada hassasiyet, duyarlılık, F1-skor; regresyonda MAE, MSE) doğru değerlendirme metriklerini kullanmayı öğrenin.
Ücretsiz ve Kaliteli Kaynak Önerileri:
Coursera - Machine Learning (Andrew Ng): Makine öğrenmesi alanında klasikleşmiş ve en çok tavsiye edilen kurslardan biridir. Temel kavramları ve algoritmaları matematiksel derinlikle ancak anlaşılır bir dille açıklar. (Genellikle MATLAB/Octave kullanır, ancak Python uygulamaları için ek kaynaklar bulabilirsiniz.)
fast.ai - Practical Deep Learning for Coders: Daha çok derin öğrenmeye odaklanmış olsa da, makine öğrenmesi prensiplerini uygulamalı ve hızlı bir şekilde öğretir. Kodlama ağırlıklı bir yaklaşıma sahiptir.
Scikit-learn Resmi Dokümantasyonu: Scikit-learn kütüphanesinin resmi dokümantasyonu, algoritmaların nasıl kullanılacağına dair detaylı örnekler ve açıklamalar içerir. Her algoritmanın arkasındaki teoriyi anlamak için de iyi bir başlangıç noktasıdır.
Google Machine Learning Crash Course: Google tarafından sunulan bu kurs, makine öğrenmesi temel kavramlarını ve TensorFlow ile uygulamalarını öğretir. Pratik uygulamalara odaklanır.
YouTube Kanalları: StatQuest with Josh Starmer, 3Blue1Brown (matematiksel sezgi için), Arpan Chakraborty gibi kanallar, makine öğrenmesi algoritmalarını ve kavramlarını görsel ve anlaşılır bir şekilde açıklar.
Proje Fikirleri ve Pratik Öneriler:
Basit Bir Regresyon veya Sınıflandırma Modeli Oluşturma: Scikit-learn kütüphanesini kullanarak basit bir veri setinde (örneğin, Boston ev fiyatları veri seti için regresyon, Iris veri seti için sınıflandırma) bir model oluşturun. Veriyi eğitim ve test setlerine ayırın, modeli eğitin ve test seti üzerinde performansını değerlendirin. Örneğin, LinearRegression veya LogisticRegression kullanabilirsiniz.
Model Performansını Değerlendirme: Oluşturduğunuz modelin performansını farklı metriklerle (örneğin, regresyon için MAE, MSE, R-kare; sınıflandırma için doğruluk, hassasiyet, duyarlılık, F1-skor) değerlendirin. Karışıklık matrisi (confusion matrix) oluşturun ve yorumlayın.
Hiperparametre Optimizasyonu: Bir modelin performansını artırmak için hiperparametrelerini (örneğin, K-NN için n_neighbors, Karar Ağacı için max_depth) GridSearchCV veya RandomizedSearchCV gibi yöntemlerle optimize etmeyi deneyin.
Aşırı Öğrenme ve Eksik Öğrenme Örnekleri: Bilerek aşırı öğrenen veya eksik öğrenen modeller oluşturmaya çalışın. Örneğin, çok karmaşık bir modelle az veri üzerinde eğitim yaparak aşırı öğrenmeyi, çok basit bir modelle karmaşık veri üzerinde eğitim yaparak eksik öğrenmeyi gözlemleyin. Bu durumları gidermek için farklı teknikler (örneğin, daha fazla veri, özellik mühendisliği, düzenlileştirme) uygulayın.
Aşama 5: Gerçek Dünya Projeleri Üretme
Teorik bilgileri ve temel becerileri edindikten sonra, veri bilimi yolculuğunuzun en önemli aşamalarından birine gelmiş bulunuyorsunuz: gerçek dünya projeleri üretmek. Projeler, öğrendiklerinizi pekiştirmenin, problem çözme yeteneğinizi geliştirmenin ve potansiyel işverenlere yeteneklerinizi sergilemenin en etkili yoludur. Kitaplardaki veya kurslardaki örneklerden farklı olarak, gerçek dünya projeleri genellikle dağınık, eksik ve karmaşık verilerle uğraşmayı gerektirir. Bu, sizi bir veri bilimcinin günlük hayatta karşılaştığı zorluklara hazırlar.
Alt Konular:
Problem Tanımlama: İyi bir veri bilimi projesi, net bir iş problemi veya sorusuyla başlar. Sadece veri analizi yapmak için değil, belirli bir değeri veya çözümü sağlamak için bir proje seçin. Örneğin, "Müşteri kaybını nasıl azaltabiliriz?" veya "Hangi faktörler ev fiyatlarını etkiliyor?" gibi sorularla başlayın. Problemi net bir şekilde tanımlamak, projenizin kapsamını belirlemenize ve doğru verilere odaklanmanıza yardımcı olur.
Veri Toplama ve Entegrasyon: Gerçek dünya projelerinde veriler genellikle tek bir kaynaktan gelmez. Farklı veri tabanlarından (SQL, NoSQL), web sitelerinden (web scraping), API'lerden veya dosyalardan (CSV, JSON, XML) veri toplamanız gerekebilir. Bu verileri bir araya getirme (entegrasyon) ve tutarlı bir formatta düzenleme becerisi kritiktir.
Uçtan Uca Proje Geliştirme (End-to-End Project Development): Bir veri bilimi projesi sadece model oluşturmaktan ibaret değildir. Veri toplama, temizleme, keşifçi veri analizi, özellik mühendisliği (feature engineering), model seçimi, eğitim, değerlendirme, optimizasyon ve sonuçların sunumu gibi tüm adımları içeren bir süreci yönetmeyi öğrenin. Her adımda karşılaşılan zorlukları aşmak ve iteratif bir yaklaşımla ilerlemek önemlidir.
Dikkat Edilmesi Gereken Temel Noktalar:
İş Problemine Odaklanma: Teknik detaylara takılıp kalmak yerine, projenizin nihai amacının çözdüğü iş problemine veya sağladığı değere odaklanın. Modelinizin performansı kadar, bu performansın iş sonuçlarına nasıl yansıdığını da açıklayabilmelisiniz.
İteratif Geliştirme: Veri bilimi projeleri nadiren ilk denemede mükemmel olur. Başlangıçta basit bir modelle başlayın, sonuçları değerlendirin ve ardından modeli veya veri işleme adımlarını iyileştirmek için iterasyonlar yapın. Bu, çevik bir yaklaşımdır ve gerçek dünya projelerinde başarı için anahtardır.
Versiyon Kontrolü (Git/GitHub): Projelerinizi yönetmek ve değişiklikleri takip etmek için Git gibi versiyon kontrol sistemlerini kullanmayı öğrenin. GitHub, projelerinizi depolamak, paylaşmak ve başkalarıyla işbirliği yapmak için vazgeçilmez bir platformdur. Bu, hem iyi bir yazılım geliştirme pratiği hem de portföyünüz için önemlidir.
Ücretsiz ve Kaliteli Kaynak Önerileri:
Kaggle Yarışmaları: Gerçek dünya veri setleri ve belirlenmiş problemlerle dolu Kaggle yarışmaları, uçtan uca projeler üzerinde çalışmak için harika bir fırsattır. Başkalarının çözümlerini (notebooks) inceleyerek farklı yaklaşımları öğrenebilirsiniz.
GitHub (Açık Kaynak Projeler): GitHub üzerinde birçok veri bilimi projesi bulunmaktadır. İlgi alanınıza uygun projeleri inceleyerek, kod yapılarını, veri işleme adımlarını ve modelleme yaklaşımlarını öğrenebilirsiniz. Kendi projelerinizi de burada barındırabilirsiniz.
Towards Data Science (Medium): Bu platformda, veri bilimciler gerçek dünya projelerini, karşılaştıkları zorlukları ve çözümlerini detaylı bir şekilde anlatmaktadır. İlham almak ve farklı proje fikirleri edinmek için harika bir kaynaktır.
Data Science for Good: Sosyal fayda odaklı veri bilimi projeleri arayanlar için çeşitli organizasyonlar ve platformlar bulunmaktadır. Bu tür projeler, hem becerilerinizi geliştirmenizi hem de topluma katkıda bulunmanızı sağlar.
Proje Fikirleri ve Pratik Öneriler:
Kendi İlgi Alanınıza Göre Bir Problem Belirleyip Çözmeye Çalışma: Hobilerinizden, günlük hayatınızdan veya çalıştığınız sektörden bir problem seçin. Örneğin, "Favori spor takımımın maç sonuçlarını tahmin edebilir miyim?" veya "Yerel bir kafenin müşteri memnuniyetini artırmak için ne gibi önerilerde bulunabilirim?" gibi. Bu, motivasyonunuzu yüksek tutmanıza yardımcı olacaktır.
Kaggle'da Bir Yarışmaya Katılma: Başlangıç seviyesi bir Kaggle yarışmasına katılın. Veri setini indirin, temizleyin, EDA yapın, bir makine öğrenmesi modeli oluşturun ve sonuçları gönderin. Liderlik tablosundaki yerinizden bağımsız olarak, bu süreç size paha biçilmez deneyim kazandıracaktır.
Web Scraping ile Veri Toplama: Belirli bir konuda (örneğin, e-ticaret sitelerindeki ürün fiyatları, emlak ilanları) web scraping yaparak kendi veri setinizi oluşturun. Topladığınız verileri analiz edin ve ilginç içgörüler elde etmeye çalışın.
Basit Bir Öneri Sistemi Geliştirme: Film, kitap veya ürün önerileri yapan basit bir sistem oluşturun. Kullanıcıların geçmiş tercihlerine veya benzer kullanıcıların tercihlerine dayanarak önerilerde bulunabilirsiniz. Bu, denetimsiz öğrenme (kümeleme) veya basit matris çarpanlarına ayırma teknikleriyle yapılabilir.
Sonuç: Veri Bilimi Yolculuğunuzda Başarılar!
Veri bilimci olma yolculuğu, sürekli öğrenmeyi, pratik yapmayı ve meraklı kalmayı gerektiren heyecan verici bir maceradır. Bu yol haritası, size sıfırdan başlayarak bu alanda sağlam bir temel oluşturmanız için gerekli adımları ve kaynakları sunmaktadır. Unutmayın ki, her büyük yolculuk küçük adımlarla başlar ve tutarlılık, bu yolculukta en büyük müttefikiniz olacaktır.
Karşılaşacağınız zorluklar olacaktır; hatalar yapacak, bazen pes etmek isteyeceksiniz. Ancak her hata, öğrenme sürecinizin bir parçasıdır ve her zorluk, sizi daha güçlü bir veri bilimci yapacaktır. Veri bilimi topluluğu oldukça destekleyicidir; sorular sormaktan, yardım istemekten ve başkalarıyla bilgi paylaşmaktan çekinmeyin.
Bu yol haritasını bir rehber olarak kullanabilirsiniz, ancak kendi öğrenme hızınıza ve ilgi alanlarınıza göre esneklik gösterin. En önemlisi, bu süreci keyifli hale getirin. Verilerle oynamaktan, yeni şeyler keşfetmekten ve problemler çözmekten zevk alın. Başarılar dilerim!



Yorumlar